


一文带你读懂深度学习:AI 认识世界的方式如同小孩
人工智能想要继续发展,也许可以从儿童学习的方法中受益。
如果你经常花时间和小孩子待在一起的话,你会不由得思考小孩子怎么能够学习得如此之快。哲学家们,比如柏拉图也曾经考虑过这个问题,但是从来没有找到一个满意的答案。我五岁的儿子,奥吉最近认识了植物,动物和钟,当然也少不了恐龙和飞船。他还弄懂了如何理解他人的需要和感受。他可以用知识来定义他看到和听到的东西,并且做出新的预测。比如他最近就说前不久在纽约市美国自然历史博物馆展示的新雷龙是食草动物,所以说并没有那么可怕。

但其实奥吉体验到的不过是一串光子到达了他的视网膜,他的耳膜接收到了空气的振动而已。他蓝眼睛背后的“神经电脑”从某种角度上来说通过他感知到的有限的信息做出了食草雷龙不是很可怕的预测。那么问题来了,是不是说电脑也可以做到这样呢?
过去15年的时间里,计算机科学家和心理学家一直在尝试找到一个答案。儿童从老师和家长那有限的输入当中获取了大量的知识。尽管如今机器智能风头正盛,但是最厉害的电脑也不能像一个5岁儿童那样进行学习。
搞清楚儿童的大脑究竟是如何运转的,然后设计出一个电子版本能够同样有效地运转,可能需要计算机科学家们几十年的努力。但同时,他们已经在开发融合了人类学习模型的人工智能了。
追根溯源
在上世纪五六十年代的第一次热潮爆发以后,接下来对AI的探索就沉寂了几十年。不过在过去的几年里,学界突然取得了重大进展,尤其是在机器学习领域。AI一时间变成了最热门的技术。这些进展究竟是拯救人类还是毁灭人类,一时间也众说纷纭。AI在也确实曾被用来预示永生或者世界末日,这两种可能性文学作品里都已经写过很多。
我觉得在AI领域取得了这些发展引起人们强烈感受的主要原因在于我们内心深处其实非常害怕类人类的出现的。不管是《科学怪人》里的魔偶还是2015年《机械姬》电影里的性感机器人,未来会出现一种“生物”会成为连接人类与人工之间鸿沟的桥梁,这种想法本身就让人觉得恐慌。
但是计算机真的能像人类那样学习吗?那些席卷媒体的热点新闻,有多少是真正具有革命意义的产品,而又有多少只是噱头而已呢?电脑学习分辨猫,或者一个平片假名的过程很难被人理解。但是仔细观察之后我们会发现,机器学习背后的基础理论并没有一开始看上去的那么难以捉摸。
但是计算机真的能像人类那样学习吗?那些席卷媒体的热点新闻,有多少是真正具有革命意义的产品,而又有多少只是噱头而已呢?电脑学习分辨猫,或者一个平片假名的过程很难被人理解。但是仔细观察之后我们会发现,机器学习背后的基础理论并没有一开始看上去的那么难以捉摸。
一种解决办法是我们接收到的光子和空气振动,到了电脑上就会以数字图像的像素和录音的声音片段呈现出来。然后试着从数据中提取一串图案用来探测并识别周围世界的物体。这种自底向上的研究方法在一些哲学家和心理学家的理论中也可以找到,比如约翰·密尔。
上世纪八十年代,科学家找到了一种令人信服的方式应用这种自底向上的方式让计算机在数据中寻找有价值的图案。”神经网络“系统通过神经元将视网膜上的光图案再现了你周围的环境。神经网络也是一样的图案。通过互相连接的类似生物细胞的处理单元将某一层网络上的像素转换成抽象的表达——比如一个鼻子或一整张脸。
神经网络的概念由于最近深度学习新技术的出现又重新振兴了。深度学习这种技术是由谷歌,Facebook和其他互联网巨头进行商业落地的。计算机不断增长的能力——比如由摩尔定律体现的计算能力的指数增长,也是这些系统获得成功的一部分原因,大数据集地快速发展也是其中一部分原因。有了更高的处理速度和更多的数据之后,连接系统能够更加高效地学习。
就像科学家一样,自顶向上的系统形成了抽象广泛的对于世界的假设。这个系统会预测在假设是正确的情况下,数据会呈现出什么样子。同时这个系统也会不断根据这些预测的结果来修改自身的假设。
尼日利亚、万艾可和垃圾邮件
自底向上的方式可能是最容易被理解的,我们首先来解释这个。想像一下你试图让计算机从你的收件箱中分辨出重要邮件。你可能注意到垃圾邮件都有某种让人讨厌的特征:收件人列表特别长,源地址来自尼日利亚或巴伐利亚,总是提到一百万美元的奖金或提到伟哥。但是很可能非常有用的邮件看起来也是这样。你不想错过表示你升职或者得了学术奖项的邮件。
如果你对比大量垃圾邮件和正常邮件之后,你会发现只有垃圾邮件一般会具备以上的讲故事方式——比如,来自尼日利亚的邮件,并承诺有一百万美元的奖金出现了问题。事实上,也许存在更加明显的区分垃圾邮件和正常邮件的方式——比如不太明显的错误拼写和IP地址。如果你能发现这些信息,你就可以准确地过滤掉垃圾邮件了,而且也不用担心你的正常邮件被拦截。
这种类似的方式也可以用来给“猫”“房子”之类的网络图片打标签。通过提取一组相同物体图片的共有特征,比如将所有猫狗区分开的图案,系统最终可以识别新图片里的猫,即便新的图片和之前的图片没有任何相似点。
一种自下而上的学习方式叫做无监督学习,现在仍处于非常初级的阶段。但是它可以检测数据中没有打上标签的图案。它仅仅寻找能够识别一个物体的特征束,比如说眼睛和鼻子通常会一起组成一张脸,这有别于背景中的树或者山。
《自然》杂志2015年发表了一篇文章解释了自下而上的方式发展的进城。Google下属DeepMind的研究者们使用了一种结合了两种不同自下而上的方式,即深度学习和强化学习,从某种角度来说能让电脑掌握玩雅达利2600电子游戏的诀窍。电脑一开始不知道游戏是如何运行的。最开始是通过随机的猜测最佳行动方式并不断接收结果反馈。深度学习帮助系统发现屏幕上的特征,而强化学习会根据特征返回一个高分。拥有该系统的电脑可以在几个游戏上都达到流畅的水准,甚至在一些案例中,电脑玩的比高级玩家还要好。也就是说,其他人类可以掌握的游戏,该系统也可以顺利掌握。
应用AI学习大的数据集,比如几百万张Instagram上的图片,邮件或者声音片段,并进行图像识别或者声音识别时,有时会得到令人气馁的结果。但即便如此,我们应该记得,在有限的数据或者训练情况下,我的孙子仍然可以准确识别动物或者回答问题。对于五岁儿童非常简单的问题,对于计算机来说仍然很困难。
要想让计算机识别出一个络腮胡子的脸需要几百万张案例,但是我们只需要几张就可以了。通过大量的训练之后,计算机可能可以识别出一只之前没有出现过的猫的图片。但是这种识别能力与人类概括的能力是不同的。因为计算机软件推理的方式不同,难免会有失误。有些猫的图片可能不会被标注为猫,也有可能会出现不是猫的图片被标为猫的情况。但即便是模糊的一瞥,人类也不会弄错。
发展之路
另外一种近些年改变了AI的深度学习方式则是自顶向下的模式。它假设我们可以从具体的数据中得到抽象的解释,因为我们已经知道了很多知识,并且大脑已经可以理解各种基本的抽象概念了。就像科学家,我们可以使用这些概念来形成关于世界的假设,并且预测假设正确的情况下会呈现出哪种情况,这是和自底向上的AI模式相反的方式。
回到刚刚我们讨论的垃圾邮件的问题,这个概念可以得到很好地诠释。之前我从某个期刊的编辑收到一封邮件,声称我在他们的期刊上发表了一篇文章,要和我讨论一下。这个编辑的名字很奇怪。这封邮件既没有尼日利亚,也没有万艾可,也没有百万美元奖金——可以说没有任何垃圾邮件的特征。但是通过我已有的关于垃圾邮件的抽象认识,我就知道这封邮件值得怀疑。
首先,我知道发送垃圾邮件的人是想通过人的贪心来从其他人那里窃取金钱。我还知道有些合法的“开源”期刊开始通过向作者征收费用来盈利了。而且我的研究领域和这些期刊毫无关系。把这些信息全部整合在一起,我得出一个可靠的假设那就是这封邮件想诱惑一些学术人士付费在这些期刊上发表假的论文。只要通过这一个例子我就可以得出这样的结论,如果我想继续验证我的假设的话,只需要使用一个搜索引擎工具来查看编辑的信誉度就可以了。
计算机科学家会把我的推理过程称为生成模型,一种可以代表抽象概念,比如贪婪和欺骗的模型。这种模型同时也可以用来描述产生假设的过程——也就是得出这封邮件可能是垃圾邮件的结论为推断过程。这个模型让我理解了这种垃圾邮件是如何运作的,但同时也让我思考了一下其他类型的垃圾邮件的模式。
在上个世纪五六十年代AI和认知科学第一波浪潮兴起时,生成模型非常重要。但是生成模型也有局限性。首先,很多事实依据的模式理论上可以用不同的假设解释。比如我刚刚提到的案例中,虽然看上去不太像,但是那封邮件也可能是合法邮件。所以,近年来学界提出生成模型需要和或然性推理结合起来,这是领域内的一次重要发展。其次,形成生成模型的基本概念的来源通常不是很清晰。
近年的一个自顶向下的方式的基本案例——贝叶斯模型也许可以解决这两个问题。贝叶斯模型是以十八世纪的统计学家和哲学家托马斯·贝叶斯的名字命名,该模型使用贝叶斯推论将生成模型和或然性理论结合起来。如果某个假设是对的,那么概率生成模型会告诉你看到对应的数据型态的可能性。如果一封邮件是垃圾邮件,那么这封邮件可能迎合了读者的贪婪之心。不过当然,一封不是垃圾邮件的邮件也可能满足读者的贪婪。贝叶斯模型将潜在假设和你看到的数据结合起来,让你清楚地分辨一封邮件到底是合法邮件还是垃圾邮件。
这种自顶向下的方式比自底向上的方式要更类似儿童学习的方式。这就是为什么过去15年里我和我的同事们一直将贝叶斯模型应用在儿童学习研究中。我们的实验室一直用这种方式来理解儿童学习因果关系的过程,并预测儿童何时以何种方式发展出新的关于世界的理解,或者更新他们已有的认知。
贝叶斯模型也是训练机器像人类那样思考的最好的方式。2015年,麻省理工学院的JoshuaB.Tenenbaum和纽约大学的BrendenM.Lake以及他们的同事在《科学》杂志上发表了一篇研究论文。他们设计了一种人工智能系统,可以认出陌生的手写文字。这件事对人类来说很容易,但是对计算机来说则非常复杂。
想想你自己的辨别能力。即便你从来没有见过日本的片假名,你还是可以发现片假名之间的区别。甚至你自己都可以重新写出一些片假名或者设计类似片假名的文字,而且你会清楚的知道片假名和韩国文字,俄罗斯文字之间差异很大。这就是Tenenbaum的团队设计的一种软件。
通过自底向上的方法,计算机会从上千张样例中找到合适的模式辨别新的文字。而贝叶斯模型则通过一个通用模型训练机器来写文字,比如笔画可以往左或者往右。当该软件写完一个文字的时候,再写下一个。
当该软件对一个现有文字进行识别时,软件可以推测出写出该文字的笔顺,然后会自动设计出一组类似的笔顺。该软件识别文字并设计笔顺的方式和我推理自己收到的邮件是不是垃圾邮件的方式是一样的,但是Tenenbaum的模型的推理过程目的在于得到想要的文字。数据一样的情况下,这种自顶向下的程序比深度学习要有效的多,甚至接近人类表现。
完美融合
自底向上和自顶向下的方式都是深度学习的有效方式,并且各有优劣。使用自底向上的方式,计算机不需要理解任何有关猫的内容,但是需要大量的数据来训练。
贝叶斯模型只需要一小部分数据,便可以大范围应用。但是这种自顶而下的方式需要对正确的假设做大量的解释。两种方式的设计者可能会碰到同样的问题。这两种方式都只适合用来解决一些简单清晰的问题,比如识别手写的文字或者猫的图片或者是玩Atari游戏。
但是儿童学习的过程却没有这种限制。发展心理学家们发现儿童在某种程度上能融合这两种方式的优点,并且最大化应用这两种方式。像我的孙子学习的时候只需要一两个例子,就像自顶而下的方式。但是他某种程度上也会通过这些数据整理出关于这些例子的抽象概念,就像自底向上的方式。
我的孙子可以做的事情还有很多。他可以很快地辨认猫和字母,甚至可以得出一些远远超出他的经验和背景知识的推断。他最近说,要是一个大人想变成孩子,就应该不吃健康的蔬菜,因为这些东西让孩子长成了大人。而我们却不知道这种富有创意的推理是从哪里来的。
当我们听到人工智能对人类是一种威胁这种观点的时候,我们应该想到人类大脑的神秘力量。人工智能和机器学习听起来很可怕,当然从某种角度来说,确实也是。部队在考虑用这些技术来控制武器。比起人工智能,人类的愚蠢有时候能带来更大的威胁,我们应该尽可能地正确地规范使用这些技术。摩尔定律早已表明,即便在理解人类思维上没有什么革命性的理论,仅仅是数据和计算能力的大量增长也可以带来计算结果的显著提升,并且产生重要的具有实质意义的结果。也就是说,人工智能的出现并不意味着颠覆世界。




 投诉建议
投诉建议
提交

2024年斯凯孚创新峰会暨新产品发布会召开,以创新产品矩阵重构旋转

禹衡光学亮相北京机床展,以创新助力行业发展新篇章

从SCIMC架构到HyperRing技术,机器人控制技术的革新
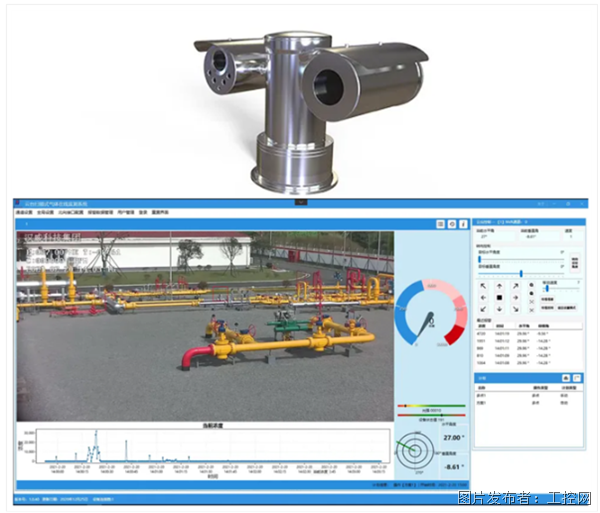
汉威科技用智慧化手段为燃气厂站构筑安全防线
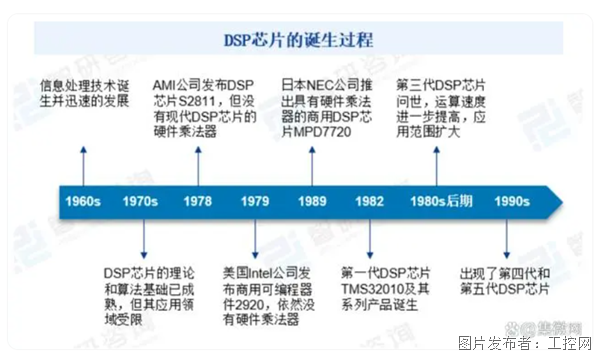
DSP应用市场的大蛋糕,国产厂商能吃下多少?