


盘点2019年全球十大AI芯片,国产芯片全面崛起!
人工智能浪潮的推动下,AI相关产业的商用场景正逐步大规模落地,基于AI技术的三大支柱:“算法+大数据+计算能力”智能应用已成为计算机最主要的负载之一。我国在用户数据方面拥有数量的先天优势,但面对有限的规模、结构固定、能耗受限的硬件制约下,如何用AI芯片处理海量的并不断演进的深度学习算法呢?跟随OFweek编辑一起来看看各大科技巨头们研发的AI芯片吧。(排名按首字母顺序排列)
1.含光800
2019年的杭州云栖大会上,达摩院院长张建锋现场展示了这款全球最强的 AI芯片——含光800。在业界标准的 ResNet-50 测试中,含光 800 推理性能达到 78563 IPS,比目前业界最好的 AI 芯片性能高 4 倍;能效比500 IPS/W,一个含光800的算力相当于10个GPU。
目前,含光800已经实现了大规模应用于阿里巴巴集团内多个场景,例如视频图像识别/分类/搜索、城市大脑等,未来还可应用于医疗影像、自动驾驶等领域。以杭州城市大脑实时处理1000路视频为例,过去使用GPU需要40块,延时为300ms,单路视频功耗2.8W;使用含光800仅需4块,延时150ms,单路视频功耗1W。
2.Graphcore IPU
总部位于英国布里斯托的Graphcore公司日前推出了一款称为智能处理单元(IPU)的新型AI加速处理器。芯片本身,即IPU处理器,是迄今为止最复杂的处理器芯片:它在一个16纳米芯片上有几乎240亿个晶体管,每个芯片提供125 teraFLOPS运算能力。一个标准4U机箱中可插入8张卡,卡间通过IPU链路互连。8张卡中的IPU可以作为一个处理器元件工作,提供两个petaFLOPS的运算能力。与芯片在CPU和GPU中的存在形式不同,它为机器智能提供了更高效的处理平台。
Graphcore公司于2016年启动风险投资计划,并在2018年12月的最后一轮融资中募集了2亿美元。基于其17亿美元的公司估值,Graphcore已成为西方半导体界的唯一“独角兽”。它的投资者们包括戴尔、博世、宝马、微软和三星。
3.Inferentia芯片
2019年,亚马逊的云服务业务AWS在其发布会AWS re:Invent上带来了高性能机器学习加速芯片Inferentia。据了解,AWS Inferentia 是一个由 AWS 定制设计的机器学习推理芯片,旨在以极低成本交付高吞吐量、低延迟推理性能。该芯片将支持 TensorFlow、Apache MXNet 和 PyTorch 深度学习框架以及使用 ONNX 格式的模型。
每个 AWS Inferentia 芯片都能在低功率下支持高达 128 TOPS(每秒数万亿次运行)的性能,从而为每个 EC2 实例启用多个芯片。AWS Inferentia 支持 FP16、BF16 和 INT8 数据类型。此外,Inferentia 可以采用 32 位训练模型,并使用 BFloat16 以 16 位模型的速度运行该模型。与EC4上的常规Nvidia G4实例相比,借助Inferentia,AWS可提供更低的延迟和三倍的吞吐量,且每次推理成本降低40%。
4.昆仑芯片
2019年尾声,百度宣布首款AI芯片昆仑已经完成研发,将由三星代工生产。该芯片使用的是三星14nm工艺技术,封装解决方案采用的是I-Cube TM。
据悉,昆仑AI芯片提供512Gbps的内存带宽,在150瓦的功率下实现260TOPS的处理能力,能支持语音,图像,NLP等不同的算法模型,其中ERNIE模型的性能是T4GPU的三倍以上,兼容百度飞桨等主流深度学习框架。该款芯片主要用于云计算和边缘计算,预计在2020年初实现量产,
5.Nervana NNP 芯片
2019 英特尔人工智能峰会,英特尔推出面向训练 (NNP-T1000) 和面向推理 (NNP-I1000) 的英特尔 Nervana 神经网络处理器 (NNP)。据了解,Nervana NNP-T 代号 Spring Crest,采用了台积电的 16nm FF+ 制程工艺,拥有 270 亿个晶体管,硅片面积 680 平方毫米,能够支持 TensorFlow、PaddlePaddle、PYTORCH 训练框架,也支持 C++ 深度学习软件库和编译器 nGraph。
Nervana NNP-I,代号为 Spring Hill,是一款专门用于大型数据中心的推理芯片。这款芯片是基于 10nm 技术和 Ice Lake 内核打造的,打造地点是以色列的 Haifa ,Intel 号称它能够利用最小的能量来处理高负载的工作,它在 ResNet50 的效率可达 4.8TOPs/W,功率范围在 10W 到 50W 之间。
6.Orin芯片
2019年NVIDIA GTC中国大会中英伟达发布了全新的软件定义自动驾驶平台——NVIDIA DRIVE AGX Orin,该平台内置全新Orin系统级芯片,由170亿个晶体管组成。
Orin系统级芯片集成了NVIDIA新一代GPU架构和Arm Hercules CPU内核以及全新深度学习和计算机视觉加速器,每秒可运行200万亿次计算,几乎是NVIDIA上一代Xavier系统级芯片性能的7倍。此外,Orin可处理在自动驾驶汽车和机器人中同时运行的大量应用和深度神经网络,并且达到了ISO 26262 ASIL-D等系统安全标准。
7.邃思DTU
由腾讯领投、融资累计超过 6 亿元的 AI 芯片公司燧原科技,在2019年发布会中推出自主研发的首款 AI 训练芯片“邃思 DTU”。
据了解邃思DTU采用格罗方德12nm FinFET工艺,480平方毫米主芯片上承载141亿个晶体管,实现2.5D高级立体封装,据称单卡单精度算力为业界第一,达20TFLOPS,首次支持混合精度,半精度及混合精度下算力达80TFLOPS,最大功耗仅225W。
邃思芯片基于可重构芯片的设计理念,其计算核心包含 32 个通用可扩展神经元处理器(SIP),每 8 个 SIP 组合成 4 个可扩展智能计算群(SIC)。SIC 之间通过 HBM 实现高速互联,通过片上调度算法,数据在迁移中完成计算,实现了 SIP 利用率最大化。
8.思元220芯片
寒武纪在第21届高交会正式发布边缘AI系列产品思元220(MLU220)芯片及M.2加速卡产品,标志寒武纪在云、边、端实现了全方位、立体式的覆盖。
思元220芯片采用了寒武纪在处理器架构领域的一系列创新性技术,其架构为寒武纪最新一代智能处理器MLUv02,实现最大32TOPS(INT4)算力,而功耗仅10W,可提供16/8/4位可配置的定点运算。作为通用处理器,支持各类深度学习技术,支持多模态智能处理(视觉、语音和自然语言处理),应用领域广泛,客户可以根据实际应用灵活的选择运算类型来获得卓越的人工智能推理性能。
9.昇腾910
2019年8月,华为在深圳总部发布AI处理器Ascend 910(昇腾910),据华为发布的参数显示,昇腾910是一款具有超高算力的AI处理器,其最大功耗为310W,华为自研的达芬奇架构大大提升了其能效比。八位整数精度(INT8)下的性能达到512TOPS,16位浮点数(FP16)下的性能达到256 TFLOPS。
作为一款高集成度的片上系统(SoC),除了基于达芬奇架构的AI核外,昇腾910还集成了多个CPU、DVPP和任务调度器(Task Scheduler),因而具有自我管理能力,可以充分发挥其高算力的优势。
昇腾910集成了HCCS、PCIe 4.0和RoCE v2接口,为构建横向扩展(Scale Out)和纵向扩展(Scale Up)系统提供了灵活高效的方法。HCCS是华为自研的高速互联接口,片内RoCE可用于节点间直接互联。最新的PCIe 4.0的吞吐量比上一代提升一倍。
10.征程二代
2019世界人工智能大会中,人工智能芯片初创公司地平线正式宣布量产中国首款车规级人工智能芯片——征程二代,并且获得五个国家市场客户的前装定点项目。
据介绍,征程二代于今年初流片成功,搭载地平线自主创新研发的高性能计算架构BPU2.0(Brain Processing Unit),可提供超过4TOPS的等效算力,典型功耗仅2瓦,满足AEC-Q100标准,算力利用率超过90%,每TOPS算力可以处理的帧数可达同等算力GPU的10倍以上,识别精度超过99%,延迟少于100毫秒,多任务模式下可以同时跑超过60个分类任务,每秒钟识别目标数可以超过2000个。
此次地平线率先推出首款车规级AI芯片不仅实现了中国车规级AI芯片量产零的突破,也补齐了国内自动驾驶产业生态建设的关键环节。
小结
目前通过CPU/GPU处理人工神经网络效率低下,谷歌大脑需要1.6万个CPU核跑数天方能完成猫脸识别训练;AIpha GO与李世石下棋时用了1000个CPU和200个GPU,AI芯片的发展是第三次AI浪潮中极为明显的趋势,算法已渗透到云服务器和智能手机的方方面面,未来每台计算机可能都需要一个专门的深度学习处理器。




 投诉建议
投诉建议
提交

2024年斯凯孚创新峰会暨新产品发布会召开,以创新产品矩阵重构旋转

禹衡光学亮相北京机床展,以创新助力行业发展新篇章

从SCIMC架构到HyperRing技术,机器人控制技术的革新
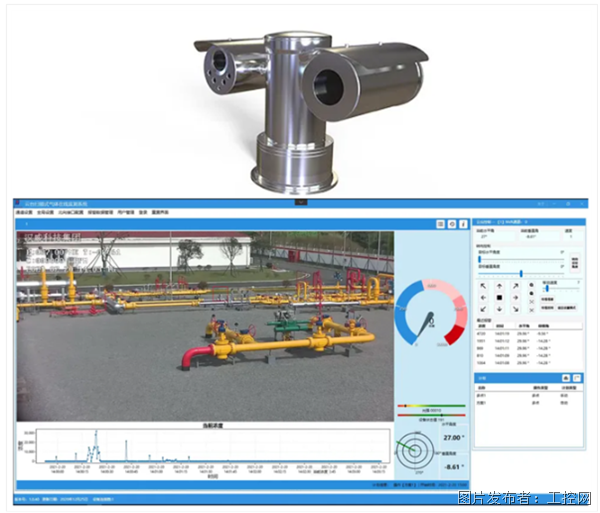
汉威科技用智慧化手段为燃气厂站构筑安全防线
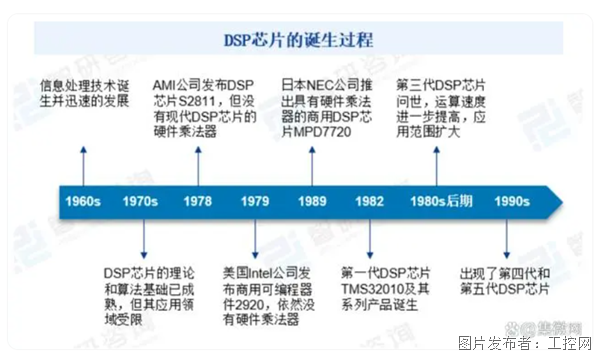
DSP应用市场的大蛋糕,国产厂商能吃下多少?